What Data Quality Really Means for Manufacturing AI (and Why “Cleaning Data” Isn’t Enough)

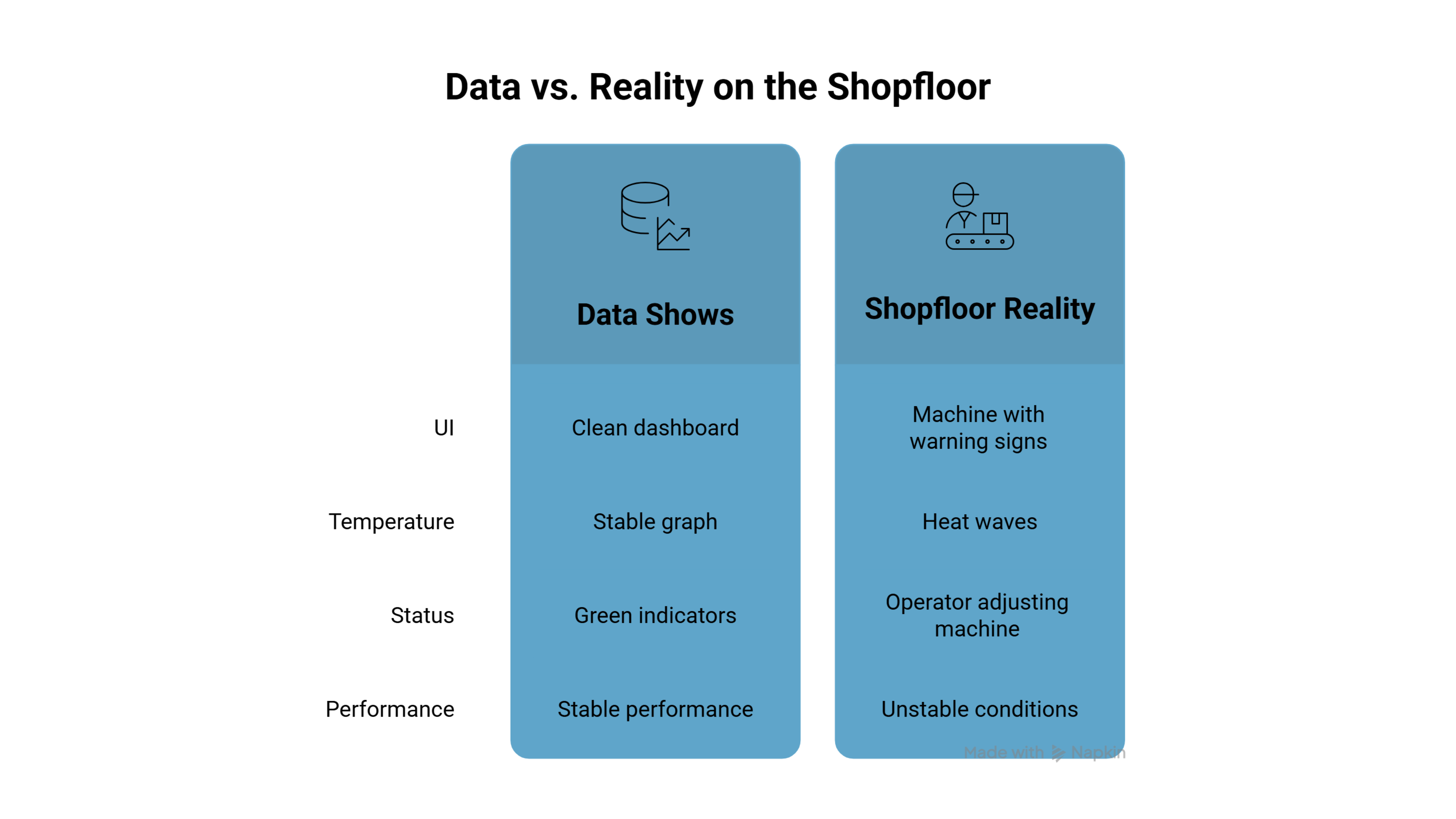
A production dashboard might show everything running smoothly. Stable readings, steady output, no visible issues.
But on the shopfloor, you’ll often see operators stepping in to adjust the line.
This gap between what the data shows and what is actually happening is where most manufacturing AI projects start to break.
That data comes from sensors, PLCs, SCADA systems, and operator logs. But in most factories, much of it is incomplete, inconsistent, or disconnected from real operations.
Treating it like clean IT data is where things usually go wrong.
In manufacturing, data quality isn’t just about fixing errors. It’s about whether the data reflects reality.
The Illusion of “Clean” Data
Most teams begin with historical data from plant historians or spreadsheets. At first glance, everything looks usable. Models trained on this data often perform well in testing.
But when deployed in real operations, performance drops.
Because the data used during training often lacks:
- Resolution (not detailed enough)
- Synchronization (timestamps don’t align)
- Context (no clear link to operations)
A value in a database may look clean, but it hides how that data was actually captured through layers of hardware, delays, and noise.
Example:
A dashboard shows stable temperature readings across a production line.
The model predicts smooth operation and suggests increasing throughput.
But on the floor, the machine is already running close to its limits. Small spikes are getting averaged out, and delays in readings hide real fluctuations.
The data looks stable. The process is not.
This is where most AI projects quietly go wrong, not because the model is flawed, but because the data gives a false sense of certainty.
Sensor Data: Where Problems Begin
Sensors are the starting point of most manufacturing data and one of its weakest links.
Factory environments are not built for precision. Heat, vibration, and electromagnetic interference constantly affect how sensors behave.
This leads to issues like:
- Noise spikes caused by electrical interference
- Signal freezing, where values stop changing even when conditions do
- Data drift, where accuracy slowly degrades over time
The problem is that these issues don’t always look like errors. A dataset can appear stable while quietly capturing distorted signals.
And once this data is used for training or decision-making, the impact is already baked in.
AI doesn’t question the data. It trusts it.
PLC and SCADA Systems: Structured for Control, Not Understanding
PLCs and SCADA systems are designed to run machines, not to explain them.
Data is structured based on system architecture, not operational meaning.
For example, a tag like PLC3_Rack2_Module4 shows where the signal comes from, but not what it relates to or why it matters.
From an AI perspective, the data exists, but the meaning is missing.
This is where many teams assume they have enough data, but still struggle to get useful insights from it.
Manual Data: The Hidden Layer of Inaccuracy
Even in highly automated environments, manual inputs still play a role.
Operators log production numbers, downtime reasons, and machine status. But these logs are often influenced by time pressure and practical constraints.
Common patterns you’ll see include:
- Rounding off numbers
- Ignoring short interruptions (“micro-stops”)
- Recording expected values instead of actual ones
Example:
A shift report shows 70% machine utilization.
Based on this, an AI system recommends tighter scheduling to improve output.
But in reality, operators may have skipped logging frequent short stops to keep reports clean. Sensor data later shows actual utilization is closer to 40%.
The result?
The system pushes for higher load on a line that is already unstable, leading to more stoppages, more defects, and more pressure on operators.
The AI didn’t fail. It followed the data.
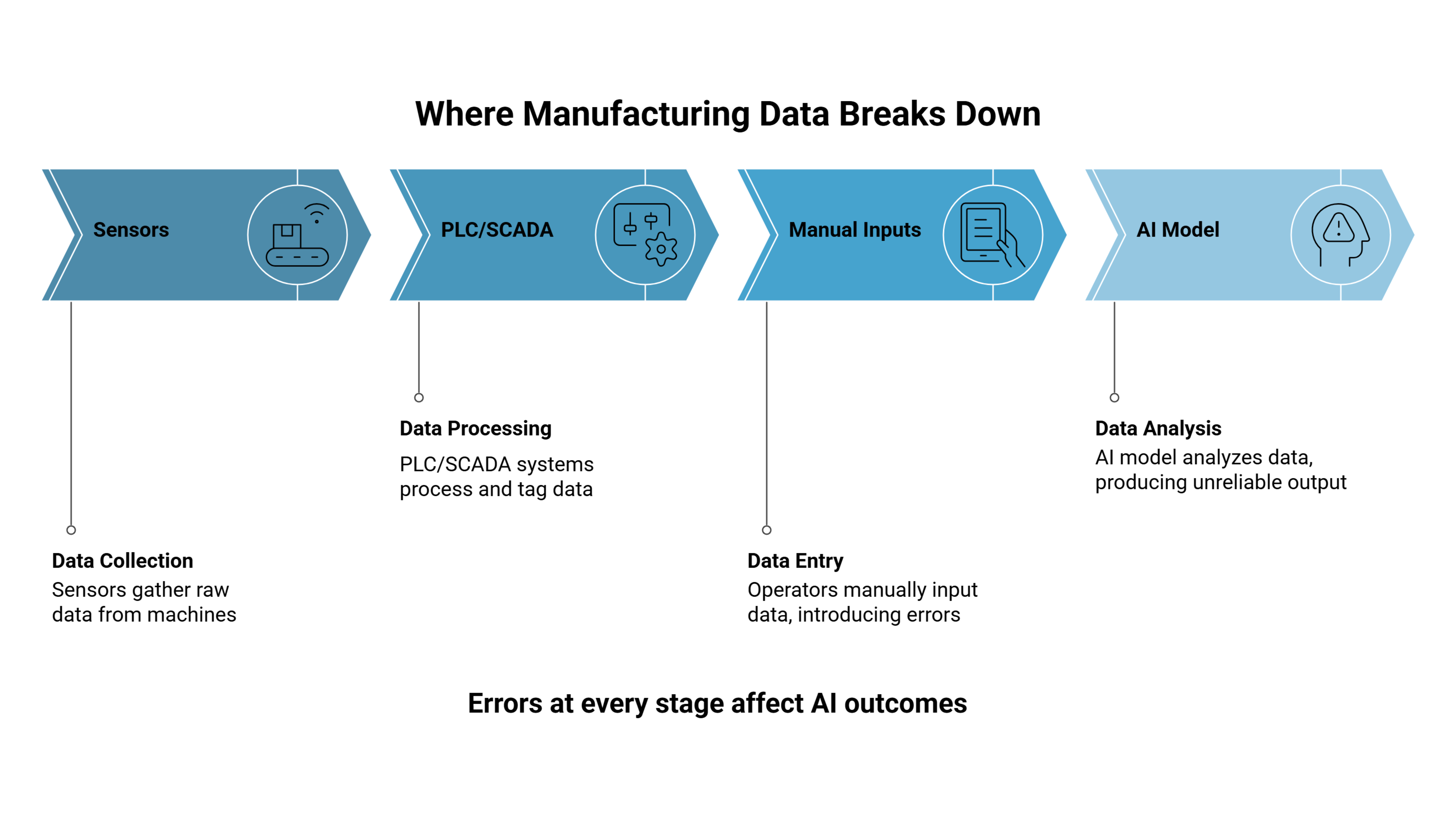
Why “Cleaning” Data Isn’t Enough
In most IT systems, data cleaning means:
- Removing duplicates
- Filling missing values
- Correcting obvious errors
But manufacturing data doesn’t fail in obvious ways.
If a sensor stops reporting correctly, replacing missing values with averages may hide serious issues. In some cases, it can even mask conditions that need immediate attention.
The problem isn’t just “dirty” data.
It’s data that looks correct, but isn’t.
To be useful, manufacturing data needs to be checked against reality:
- Does this value make physical sense?
- Does it match how the machine behaves?
- Is it consistent with nearby signals?
Without this, even “clean” data can lead to wrong decisions.
Bridging the Gap with Better Data Capture
Improving data quality requires moving beyond passive data collection.
Instead of just storing signals, systems need ways to validate what is actually happening on the shopfloor.
One approach gaining traction is using vision-based systems to validate what sensors capture.
By adding visual context, these systems help identify gaps between recorded data and actual conditions on the shopfloor.
Platforms like Seewise apply this approach to improve data reliability without changing existing systems.
From Clean Data to Operational Truth
Improving data quality in manufacturing is not a one-time cleanup exercise.
It requires a shift in mindset, from fixing data after the fact to ensuring it reflects reality from the start.
That means:
- Validating data closer to the source
- Connecting data to real operations
- Reducing dependence on manual inputs
- Catching inconsistencies early
Manufacturing AI depends on data that reflects what is actually happening, not what appears to be happening.
If that gap remains, no model will fix it.
At the end of the day, AI is only as reliable as the data it learns from.
And on most shopfloors today, that data is still far from trustworthy.

What Data Quality Really Means for Manufacturing AI (and Why “Cleaning Data” Isn’t Enough)